

Update: Fifty years ago today—April 11, 1970—the world watched as Apollo 13 launched towards the skies. Over the years, the rest has become both history and NASA legend. You may know the Tom Hanks-led Hollywood rendition of the story, but as part of our docuseries celebrating the 50th anniversary of the Apollo program, Ars connected directly with some of the brave people of NASA involved directly in this harrowing experience. Given this launch anniversary, we're resurfacing the episode of Apollo: The Greatest Leap focused on saving the crew of Apollo 13. This story and video first appeared on Ars on February 6, 2018, and it appears unchanged below.
As Apollo 13 astronaut Fred Haise floated in the tunnel snaking between the Lunar Module and Command Module, he heard—and felt—a loud bang. Around him, the two vehicles began to contort. Then, the metal walls of the tunnel crinkled as the spacecraft shuddered.
Wide-eyed, Haise scrambled from the tunnel into the Command Module alongside Jack Swigert and their commander, Jim Lovell. From his customary position at Lovell's right, Haise quickly assessed something was drastically wrong with the spacecraft's cryogenic tanks—the oxygen was just gone. Fortunately, there didn't seem to have been a chemical explosion, because only a thin wall separated the oxygen tank from the propellant tanks used to power the spacecrafts main engine.
“It really didnt explode like something you think of with shrapnel,” Haise told Ars, in an interview. “It just over-pressurized, and then it let go some steam. If it had been a shrapnel-type explosion, I wouldnt be here today.”
The incident took place April 13, 1970, near the end of the second full day of the Apollo 13 flight. The crew aboard NASAs third mission to the surface of the Moon had just completed a live television broadcast. They were tired but also excited. They were supposed to go to bed soon, and when they woke up, the spacecraft would enter lunar orbit. Within about a day, Lovell and Haise were set to become just the fifth and sixth humans to walk on the surface of another world.
But now, seated in the Command Module Odyssey, contemplating the loss of an oxygen tank, Haises first thought was not for any danger Apollo 13 might face returning home. In the immediate aftermath of the accident, death did not seem so imminent. Rather, Haise lamented the lost opportunity to set foot on the Moon.
“I was just sick to my stomach with disappointment,” Haise recalled. “I knew we had an abort, and Id lost the landing. That was my main feeling. We thought we had a second tank that was intact.”
But the damage was such that the second tank was also affected. It may have been leaking oxygen more slowly, but the leak had begun all the same. Soon, the spacecraft would lose both of its oxygen tanks. This didnt matter so much for oxygen inside the Command Module, as the astronauts had enough to breathe. But without the oxygen tanks, the spacecraft could not operate its fuel cells. The crew of Apollo 13 would have no power. They faced the prospect of freezing to death in outer space.
As the astronauts and flight controllers in Mission Control realized they could not stop the leak in the second oxygen tank, the mission suddenly changed. No longer would Apollo 13 seek to land on the Moon. Their mission had become one of survival.
“So many chances”
Even before the Apollo 13 accident, some senior NASA managers had wondered how long they could get away with the grave risks posed by going to the Moon. Given all of the different aspects of a lunar flight—from the Saturn V launch vehicle, to the Command and Service Modules, and finally the Lunar Modules—an awful lot of very complicated components had to work just right for mission success.
At the outset of the program, NASA had formally established the target probability of overall success for each Apollo mission—a landing and return—at 90 percent. Overall crew safety was estimated at 99.9 percent. But a 1965 assessment of these risks had found that, based upon the current plans and technology, the probability of mission success for each flight was only around 73 percent, while rated per-mission crew safety sat at 96 percent.
Few people lived day-to-day with these risks and concerns more than Robert Gilruth. His fame may have receded in recent decades, but Gilruth stood above all others in Americas efforts to send humans to the Moon and back. After NASAs creation, the fledgling agency had turned to Gilruth to lead the Space Task Group to put a human into space before the Soviet Union. Later, after President John F. Kennedy called for Moon landings, that task fell to the Manned Spacecraft Center in Houston, which Gilruth directed.

An aeronautical engineer from a small town in Minnesota, Gilruth had a more pragmatic view of human spaceflight than Kennedy's grand vision. As he saw it, after NASA had successfully put astronauts into orbit with the Mercury program, the next logical step toward a permanent presence in space would have been to build a space station there.
“But that didnt have the flair that was needed at the time, in the eyes of Mr. Kennedy,” Gilruth, who died in 2000, recalled in an oral history. “He thought going to the Moon was about as good a thing as you could possibly do. I think LBJ liked that, too. Nobody in NASA would say they couldnt. I at least said that Im not sure we can do it, but Im not sure we cant.”
Gilruth had no illusions about the challenge of reaching the Moon. Moreover, once Neil Armstrong and Buzz Aldrin stepped onto the Moon before a global television audience, NASA had achieved Kennedys mandate. If each mission had a one-quarter chance of not landing on the Moon and a non-negligible chance of losing a crew, why keep at it? That feeling only grew within Gilruth as NASA accomplished more Moon landings.
“I put up my back and said, We must stop,” Gilruth said. “There are so many chances for us losing a crew. We just know that were going to do that if we keep going.”
Listing image by NASA / Aurich Lawson
Apollo 12
One of those chances came seconds into the second flight to the lunar surface, in late 1969. A cold front swept through the Florida peninsula on November 12, as the Apollo 12 rocket was fueled under rainy, foreboding skies. But no active thunderstorms threatened the launchpad, so the mission countdown proceeded as planned. Part of the reason might have been that President Richard Nixon was watching from nearby.
What no one realized, however, is that danger lurked in the clouds overhead. From about 1,000 to 20,000 feet up, even though they were not producing lightning, these clouds contained a significant amount of electrical charge. After the rocket launched, at just 36.5 seconds into the flight, lightning struck the launch vehicle, and it happened again 15 seconds later. Each bolt contained about 10,000 amperes of current at its peak.
A post-launch analysis determined that the Saturn V had initiated the lightning strikes within the electrified clouds. This is because the accelerating booster and its ionized exhaust plume tunneled an electrical conduction path through the atmosphere, and this rocket-enhanced electrical field triggered lightning discharges.
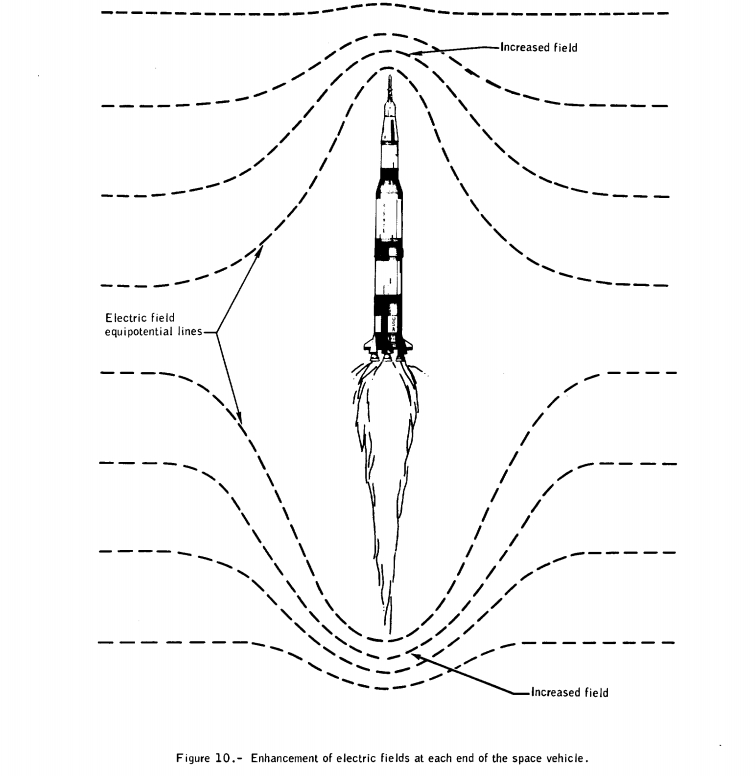
But no one in the rocket or inside Mission Control realized this at the time. The lightning strikes had knocked offline many of the sensors and instruments inside the Apollo Command Module, and the spacecraft began transmitting nonsensical telemetry data to the ground. More troubling, the lightning had wiped out the Command Modules carefully calibrated guidance and navigation platform. That meant, at minimum, that the crew would have to perform a lengthy procedure in orbit to recalibrate it.
Shortly after the strikes, the missions commander, Pete Conrad Jr., called down to Houston. “Okay, we just lost the platform, gang,” he said. “I dont know what happened here; we had everything in the world drop out.”
In Mission Control, Gerry Griffin was only a minute into directing his very first flight, and now he faced an emergency call. Should he demand an abort? He had just seconds to decide. What unfolded next has become a legendary moment in NASA history.
One of the brightest minds in Mission Control, John Aaron, sat at the Electrical, Environmental, and Consumables Manager (EECOM) console that day. From simulations, Aaron recalled seeing a similar pattern of nonsense telemetry data when the power supply to a piece of hardware inside the Command Module called the "Signal Conditioning Equipment" (SCE) had failed. Aaron deduced that switching this SCE box to its backup mode would bring it back online and begin transmitting correct telemetry data down to the ground. From this, flight controllers should be able to determine whether the crew of Apollo 12 were flying a sick or healthy bird.

“Try SCE to Aux,” Aaron said. Although Griffin didnt quite understand the significance of this message, he trusted his flight controller. The message was conveyed to the spacecraft by the CAPCOM, which was being run by astronaut Gerald Carr.
What the hell is that?
The Signal Conditioning Equipment was a component of the Command Module's complicated communications suite. It was responsible for converting raw signals from a variety of on-board instruments into voltages compatible with the spacecraft's gauges and with equipment on the ground. Without it, the CM was effectively transmitting gibberish. Setting "SCE to Aux" toggled the SCE to a low power mode that would function on the CM's batteries and cleared up the telemetry feeds.
“FCE to Aux?” Conrad replied. “What the hell is that?”
“SCE, SCE to auxiliary,” Carr told him again.
Alan Bean, sitting next to Conrad, recognized the command and flipped the switch. Almost immediately, power came back on to systems within the spacecraft. Mission Control began receiving good telemetry data. Griffin cleared the crew to continue its flight to orbit. A few days later, NASA had landed safely on the Moon for a second time. (This incident is dramatized pretty faithfully in the HBO miniseries From the Earth to the Moon.)
If nothing else, the lightning strike had validated one of NASA's design choices: because the Saturn V had been envisioned as one day carrying cargo in addition to humans, the rocket had been designed with its own independent guidance system that was used during launch. Although the lightning had reset the Command Module's guidance platform, the Saturn V's internal systems were undamaged and kept the rocket solidly on course. If the booster hadn't had its own guidance and had instead depended on the Apollo CM's computers, things would have gone very differently—it would have been an aborted launch at best. At worst, the crew could have been killed.
After the mission and subsequent investigation, NASA changed some of its launch rules. No longer would rockets be allowed to launch within five miles of thunderstorm clouds or three miles of associated anvil clouds. They could not launch through middle cloud layers 6,000 feet or greater in depth where the freeze level is in the clouds, nor through cumulus clouds with tops at 10,000 feet or higher.
Perhaps, managers thought, NASA just had its biggest close call moment in the Apollo program, and by responding admirably in a time of duress, the crew and Mission Control had proven their mettle. But as it turned out, NASA would have worse luck soon. The space agency had only barely begun to plumb the depths of its flight controller talent.
Worst-case scenario
Everyone knows the story: Apollo 13 was an uneventful routine mission with a low level of public interest—right up until something blew up and "routine" was pitched out the window. Things went wrong that shouldn't have been able to go wrong, but quick thinking by Chris Kraft's cadre of steely eyed missile men saved the day.
And setting aside nuance and detail, the explosion that crippled the Apollo 13 Command and Service Module did indeed have a relatively straightforward cause: it was triggered by a spark inside a damaged supercritical oxygen tank. Easy, right?
As so often happens with problems in real life versus problems in movies, digging into the “why” of the tank explosion reveals a sequence of mistakes and oversights that stretch back years before Apollo 13 launched from Pad 39. The contractor responsible for the tanks construction and testing holds some share of the blame; NASA ground engineers contributed their share; even the Apollo 13 crew had a role to play in the root cause.
In the end, the explosion occurred because of a messy confluence of things gone wrong. It arose out of acts of poor improvisation and because of incorrect (or incorrectly followed) documentation. It was, ultimately, a human-caused problem rather than a design issue—although many designs were changed after Apollo 13 to minimize the impact of such an event recurring. NASA if nothing else has an unmatched talent for fixing barn doors after horses escape.
The cause, part one: The yanked tank
Don't be so critical
Youll almost always see the Apollo CSM tanks referred to as “liquid oxygen tanks” and “liquid hydrogen tanks,” but in reality the Apollo CSM actually carried its cryogens in a supercritical state, rather than liquid. This was done for a variety of reasons, most of which have to do with the difficulty of handling cryogenic liquids. For the sake of convenience—mainly because typing “supercritical oxygen” is a lot longer than typing “LOX”—we use “liquid oxygen” and “liquid hydrogen” and their abbreviations throughout this piece.
The problematic liquid oxygen tank was “tank number two,” the second of two spherical LOX tanks housed in the spacecrafts Service Module. The Apollo CSMs primary source of power was three large fuel cells, which generated both electricity and water (for the crew to drink and to cool the spacecrafts systems) by combining liquid oxygen and liquid hydrogen in an electrochemical reaction; both LOX tanks were plumbed into all three fuel cells.
But the number two tank began life assigned not to Apollo 13s Odyssey CSM, but to Apollo 10s Charlie Brown. During the run-up to Apollo 10 in 1968, it was discovered that the tank wasnt quite fitting properly in Charlie Browns equipment bay, so the decision was made to swap the number two tank with its twin from the under-construction Odyssey. But during the removal procedure, the ground team missed disconnecting a single retaining bolt, which led to the tank assembly being dropped from a height of about two inches. The drop happened in such a way that some of the internal plumbing became misaligned.
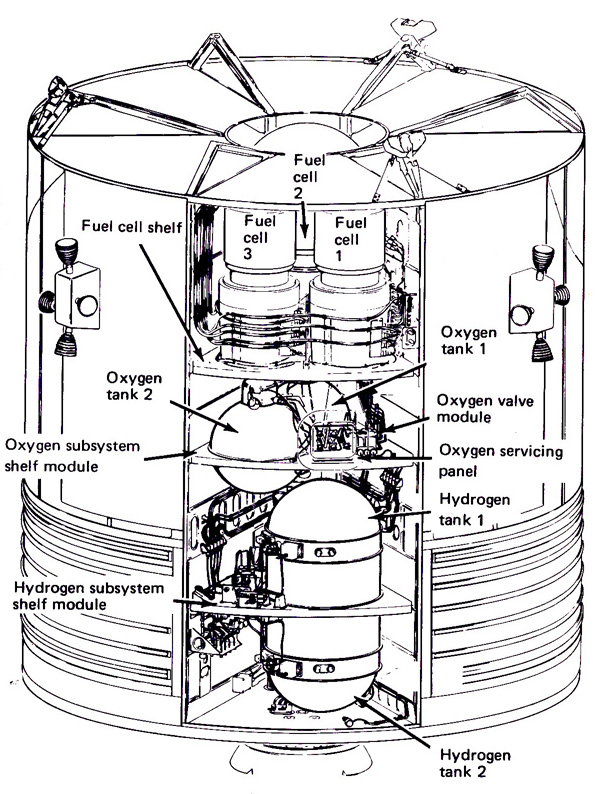
NASA performed an inspection and assessment of the tank and determined—incorrectly—that the likelihood of damage from the drop was low. It appeared that the tanks fill line—used primarily during ground testing and checkout—had possibly been jarred loose from its fitting, but the fill line wasnt used during flight and the misalignment was adjudged to have no potential mission impact.
The cause, part two: The foiled boil
The tank remained untouched for two years, until March of 1970, when the Apollo 13 spacecraft was being run through its countdown demonstration test. The test involved filling the spacecraft up with all its cryogens and verifying that everything functioned during a simulated countdown to launch. The test came off without incident, and tank two performed as it was supposed to.
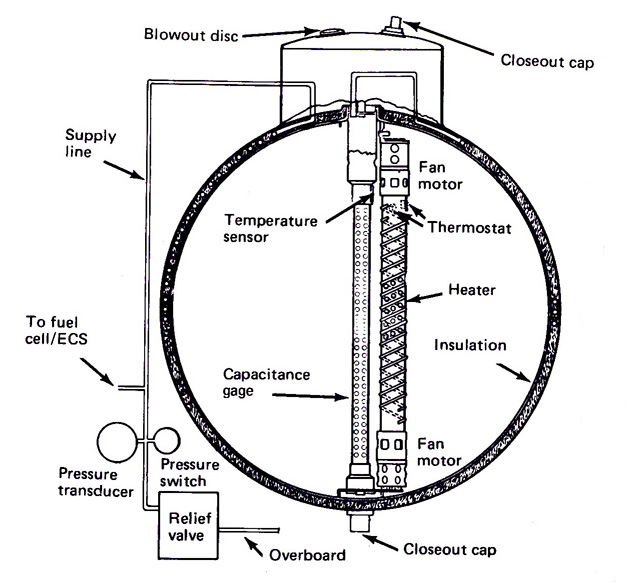
However, when it came time to purge the tank of LOX, the ground crew discovered that the damaged fill line was interfering with the LOX purge procedure. The usual method of purging the tank was to pump it full of gaseous oxygen via the fill line to displace the LOX, and the technicians werent able to make the procedure work because of the fill line damage.
In an alternate procedure signed off on and approved by Apollo 13 Commander Jim Lovell, the ground team then attempted to empty the tank by boiling off the liquid oxygen rather than draining it. This involved connecting the tanks heater to ground power and raising its internal temperature to about 81 degrees Fahrenheit (27 degrees Celsius). The idea was that the ground team would open the tanks drain line, crank on the heater, and let the heated LOX slowly evaporate over the course of two days.
However, there was a problem with this plan.
The contractor responsible for the tanks construction and checkout was Beechcraft (née Beech Aircraft Corporation). When Beechcraft originally landed its Apollo subcontract, the specifications it was given to build tanks required those tanks to function on 28 volts of DC power, which is what the tanks would be supplied by the Apollo CSMs on-board power systems. NASA later amended those specifications to require the tanks to also function on 65VDC so that higher-voltage ground equipment could be used for faster filling and testing.
Beech built the tanks and subcontracted out the electrical switches to another manufacturer. But for reasons that remain unclear—but which probably come down to an honest failure of oversight in a project with a huge number of moving parts—Beech never informed its switch subcontractor about the voltage specification change, nor did the company retrofit existing tanks with beefier 65VDC-rated switches.
The cause, part three: The heater meter
When tank two was connected to 65VDC of ground power, the current caused its 28VDC-rated thermostatic safety switches to fuse closed, allowing power to flow unimpeded to the tank heater. The higher current and lack of an “off” switch caused the heater to vastly overshoot the desired temperature. But even as the temperature in the tank spiked, the ground technicians might still have been able to spot the problem and save the day, if not for another oversight: the tanks thermometer wasnt capable of displaying temperatures over 85 degrees Fahrenheit (about 30 degrees Celsius).
Technicians watching the test were aware only that they should make sure the temperature didnt rise above 85 degrees Fahrenheit, and thats what the temperature gauge showed. They were unaware that the gauge couldnt display a higher value.
Rather than cycling on and off via the action of its thermostatic safety switches to maintain a comfortable 81 degrees Fahrenheit, tank twos heater remained full-on under 65VDC of juice. The tanks internal temperature rose to more than 1,000 degrees Fahrenheit (about 540 degrees Celsius) and stayed there for about eight hours. The heat was so extreme that it warped and cracked the Teflon insulation around the tanks internal wiring, likely exposing bare metal in multiple places.
The stage is set
In the film Apollo 13, its a dramatic moment: Kevin Bacon flips a switch, sparks fly and gas shoots everywhere, and Tom Hanks delivers one of the most famous misquotes in the history of cinema (mission commander Jim Lovell actually said, "Houston, we've had a problem").
Reality never really mirrors what happens on the silver screen, but this time, Hollywood got it pretty close. About 56 uneventful hours into the flight, Command Module Pilot Jack Swigert was performing a set of routine housekeeping tasks on Odyssey. One of those tasks was called a “cryo stir,” a procedure that involved briefly activating fans inside of the cryogenic fuel tanks in order to de-stratify the supercritical materials so the tanks sensors could more accurately judge how full the tanks were.
But O2 tank two's damage ensured the routine was about to become anything but. The cryo stir caused something to happen with tank twos damaged wiring—a change in resistance, or a shift in position, or some other triggering event—and the wiring sparked.
Teflon is, under normal circumstances, stubbornly non-reactive—indeed, its utter refusal to catch fire is one of the things that makes it an excellent insulator to wrap around wires. However, as is the case with most material, Teflon behaves much differently under high pressure and when immersed in supercritical oxygen. Rather than being safely non-flammable, it burns.
The spark ignited the wire's Teflon insulation (and, likely, the metal of the wire itself). The combustion raged in the tank for about 16 seconds, causing the tanks pressure to spike up past 6,000psi (about 41MPa). This massive overpressure compromised the tanks structure and blew its dome off, which in turn caused secondary mechanical shock effects all throughout the spacecraft (including closing the reactant valves for two of the three fuel cells). Over the course of the next four seconds, the combustion and its gases spread through the Service Modules equipment bay, feeding on more Teflon and now also Mylar insulation inside the Service Module. The pressure ultimately grew so great that one of the Service Modules side panels blew off, exposing the fire to space.

The vacuum quickly stopped the combustion, but the damage had been done: Odyssey was gutted, and her ability to generate power was effectively gone. Flight controllers had to grapple with a completely upended mission—it quickly became apparent to them, as it had become apparent to Lunar Module Pilot Fred Haise, that landing on the Moon was no longer a possibility. At first, confused by a supposedly impossible sequence of failures, controllers chased the possibility that the problem was with their instrumentation—even though Apollo was state of the art by the technology of the day, the equipment was still prone to problems, and instrumentation was generally suspected as the cause of most issues unless proven otherwise.
But as the situation evolved over the course of the first hour, it became extremely obvious that the problem was real, very real.
Quis custodiet?
It's important here to pause and explain the division of labor between the crew on the spacecraft and the flight controllers on the ground. When NASA's first Mercury flights were still on the drawing board, a subset of engineers at the nascent Space Task Group (itself an outgrowth of the civilian NACA agency, which had in 1958 found itself suddenly re-chartered as NASA) were charged with developing from scratch the set of procedures and rules governing how a space launch might be controlled and managed. Their efforts to map out all of the questions about "who does what" and "when do they do it" resulted in what we think of as the classical vision of "Mission Control"—a group of skinny-tie-wearing bespectacled geniuses with well-protected shirt pockets, bent over dazzling retro-futuristic consoles in a dim room hazy with cigarette smoke and tension.

The reason for those fancy consoles boiled down to the fact that very early on, the STG Mission Control designers (headed by a young Chris Kraft) realized that the spacecraft they were building were too damn complicated. The astronaut selection criteria meant that the people being chosen to fly the spacecraft were all skilled test pilots with lightning reflexes and the ability to make complex decisions very quickly under high stress, but they were going to be busy enough just with the business of flying. If they ran into a situation that required deep engineering knowledge in addition to stick-and-throttle skill, they might not even be able to adequately describe their problems before they were injured or killed—the Apollo spacecraft just had too much going on for the crew to keep tabs on.
So by necessity, watching over all of a spacecraft's huge list of complex systems was a task given to the ground, where dozens and dozens of pairs of eyes could pore over tremendous amounts of detail about each system. The astronauts themselves could then enjoy a much more limited view of the spacecraft's internals and could focus on more astronaut-appropriate tasks, like flying, rendezvousing, docking, landing, and running experiments.
When everything was going how it should be going, all the various consoles in Mission Control—along with each controller's team of backroom analysts and assistants, who kept track of even more systems—spent their time observing the behavior of the spacecraft, keeping tabs on the health of all its myriad components, tracking its state vector (the spacecraft's position, attitude, and velocity) and ensuring the spacecraft was on course, continually updating a set of abort procedures and trajectories for use if the spacecraft suddenly had to return to Earth, and ensuring that the mission was proceeding on its carefully calculated (and often tightly packed) timeline.
Conversely, the crew themselves had very little insight into what their ship was doing. The bewildering array of instrumentation in the Apollo spacecraft cockpit dealt mainly with guidance, environmental controls, communications, and the electrical systems—things they needed to be able to troubleshoot if they were out of contact with the ground. The on-board Apollo Guidance Computer could (via a laborious and error-prone process of manual keypresses) display plenty of additional information about the spacecraft—particularly when it came to guidance and rendezvous tasks—but the crew was, by design, not burdened with the hundreds of screens of information on thousands of systems that the ground controllers had to keep track of.
Those screens weren't terribly great, either. The rows and columns of figures controllers watched on their consoles weren't sharp raster images—instead, they were blurry composites most often generated by a camera pointed at another screen elsewhere in the building. Static details like column and row labels were created by interposing a slide (as in an actual physical photographic slide) between a screen full of raw numbers and another camera, and then transmitting that composite image to the controller's screen. This layer-upon-layer approach, coupled with already-fuzzy 1960s' vacuum tube-based CRTs, made actually tracking data a difficult, eye-straining affair.
To keep from having to squint through a catalog of hundreds of "channels" of different screens all the time, controllers' consoles were also wired with a dizzying array of system-specific warning lights, each of which was hard-wired to some aspect of some relevant spacecraft system. The lights were usually "limit sense" lights, which could be configured to light up when some system value crossed a preconfigured high or low threshold; controllers were trained through exhaustive simulation to know which detailed screen "channel" to consult based on which lights lit up under varying circumstances.
The (somewhat misconfigured) EECOM console as it existed in MOCR2 prior to the 2018 restoration. Steven Michael The EECOM console as it was configured for Apollo 15, showing a more correct panel layout. NASA
But even this was, by today's standards, shockingly primitive. Back in 2012 during a tour of historic Apollo Mission Control room two, flight controller Seymour "Sy" Liebergot explained to Ars the limitations of the system:
"We would set limits tighter than the fail limits, the upper and lower limits, of a parameter," Sy explained, standing by his EECOM desk and pointing at the row of event notification lights atop the dual displays. "We'd set them a little bit tighter so we could be alerted to a change off the nominal. For example, the cabin pressure was 5.0 [PSI]; if it went to 5.5 or down to 4.7, we would get alerted." This kind of a deviation would cause one of the limit sense lights to illuminate, showing the system and parameter which was misbehaving. The controller would then know which display page to call up on his console's screens.
"We could go look up what that was and then we would look down on the display and we would have an asterisk next to that parameter," he continued. Relying on the notification panel to direct them to problems saved the controllers from having to continually sweep through all of the different video pages on their displays manually. The system was refined further after Apollo 13. "What happened there was that so much failed nearly at the same time," Sy continued, "that it was just a big cascading failure and you just couldn't tell where it started." In response to this, new critical systems monitoring panels were added which would light up if a critical parameter deviated and then remain lit, even if the system drifted back into normal range—prior to that, the limit sense lights would go dark if a system's parameters returned to normal. This change was crucial, since, until Apollo 14 when the changes were made, a transitory problem might go unnoticed if too many other things were happening at once.
This, then, handily explains one of the big problems with the initial effort to diagnose the Apollo 13 explosion: with so many cascading problems and so many systems moving into and out of safe limits, controllers literally couldn't keep track of everything that was going on. Their consoles didn't even keep the trouble lights illuminated after a system moved back into its normal bounds. There also wasn't a fast way to scroll back through more than a small subset of recent data. The telemetry was all being dutifully recorded on reel-to-reel, but playing it back involved a lot of physical work to actually go pull the reels and wasn't possible in the midst of crisis.
So when an event like Apollo 13's explosion happened, it was difficult for the astronauts and ground controllers to figure out what the hell was really going on.
Inconceivable
The common public perception of the events that followed is heavily influenced by Ron Howard's 1995 eponymous dramatization of the mission. It's a fine film—we're huge fans here at the Orbiting HQ—but the necessities of the medium and the requirement to fit the story to a typical movie structure mean that the film is a mix of fact, sort-of-fact, and convenient confabulation. Many of the film's dramatic beats (such as the filter construction) are shown out of order from when the events actually happened; many others (like the astronauts shouting at each other in the capsule) are simply made up. Life is not a movie, and real events rarely break down into three structured acts.
Still, as dramatizations go, Apollo 13 got far more right than it got wrong—especially the tone and attitude of controllers on the ground fighting to save the crew. Even in the first hour, as problems stacked up on top of problems, it was inconceivable to the people in Mission Control that the crew might not make it home. They might come home exhausted and dehydrated and hungry, but not making it home at all? The possibility didn't seriously enter anyone's mind, because even though the spacecraft was exhibiting failures far in excess of any simulation, there were always more things they could try.
One of those controllers was Sy Liebergot, played in the movie by Ron Howard's brother, Clint. Liebergot worked the EECOM console, where he was responsible for monitoring the electrical, environmental, and communications equipment (or consumables, depending on which version of the acronym you like better) on the Command Module (a similar but separate position, called TELMU, existed for monitoring the Lunar Module). Liebergot was nearing the end of his shift when the accident occurred, and he witnessed the explosion not as a single dramatic event, but rather as a torrent of signs: confused and conflicted readings on his screens, the bank of status lights that adorned the "eyebrow" of his console, an overlapping mix of multiple conversations happening at the same time between his backroom staff (with their deeper view into the spacecraft's systems) and Flight Director Gene Kranz, who was pushing hard for some kind of information on what was going on.

The key to Apollo's ultimate success could be smartly summarized in the motto of the Boy Scouts: "Be prepared." Controllers and crews had trained exhaustively and totally for each mission, both separately and together in massively complex "integrated sims" that linked hundreds of people at Cape Canaveral and Houston (along with other NASA centers and contractor support sites) into a huge continent-spanning simulation of what everyone would be doing during an actual mission.
The simulation technicians, under the tutelage of supervisors ("SimSups") like Dick Koos and Bob Holkan, found a perverse joy in creatively killing crews and punishing controllers, but there was always one unbreakable rule in all the simulations: there had to be a way to win. At no point were the simulation supervisors allowed to introduce a scenario with no way out. Even when the simulations were at their worst quadruple-failure craziness, there was never a Kobayashi Maru moment. This was for a variety of reasons, but the most important was that there was no value in training for failure—the flight controller ethos was such that failure, famously, was not an option.

This brutal level of training often pushed everyone to their mental, physical, and emotional limits, but it resulted in a group of professionals with an unmatched level of familiarity with their systems and their spacecraft—to the point that the best controllers, like John "SCE to AUX" Aaron, could rattle off from memory the varying symptoms that would emerge from failures of individual transistor gates on the spacecraft.
However, this level of deep preparedness and intimate technical familiarity had an enormous downside: it conditioned controllers to look first at the systems themselves as the cause of any potential problem that came up. When Odyssey's O2 tank two exploded, controllers sunk more time than they should under the assumption that the problem was related to instrumentation, rather than the possibility of a physical event. After all, "let's just blow up the spacecraft and see how they handle it" was verboten in simulations—there always had to be an out, however deviously hidden it might be under layers of misdirection.
With that in mind, when pressed by Kranz for information, Liebergot's first response was somewhat predictable: "We may have an instrumentation problem, FLIGHT."
Speaking to IEEE Spectrum in 2005, Liebergot recounts the tale with chagrin: “It was the understatement of the manned space program. I never did live that down."
Hype versus reality
A quick note
Portions of the "Hype versus reality" segment of this article are reproduced from our previous Apollo 13 explainer, originally published in April 2015.
As with any real-world crisis, there is no quick and easy way to present the timeline in the immediate aftermath of the explosion—multiple lines of inquiry were happening simultaneously, with multiple voices yammering for attention in the ear of Flight Director Kranz. About an hour after the explosion, as it was becoming clearer what had happened, Mission Control underwent a shift change and Glynn Lunney replaced Kranz in the big chair. Lunney had been monitoring the situation for the past hour and had been communicating with Kranz throughout. The crisis unfolded in an odd combination of car-crash suddenness and deliberate slow motion.
"Sort of a dawning was going on," explained Lunney in Apollo: The Race to the Moon. "Gene worked the problem with the guys and I sat there and listened to it… It wasn't a thing where immediately you knew, 'Boy, we've blown the tanks and we gotta get this thing back from the Moon and power up the [Lunar Module].'" Rather, it was a series of dawning revelations, supported by data, that each pointed to a course of action.
Still, considering the overall length of the crisis and the time spent getting a handle on the problems, the major decisions on how to get the crew home were made with almost stunning rapidity. Liebergot shared with Ars a slide from a presentation he gives on crisis decision-making, showing that almost every major life-critical decision happened within about six hours after the explosion:

Famously, Liebergot plays down his contributions to the immediate management of the crisis. "The only thing I did was not get up and run off!" he told Ars.
Just under two hours after the initial explosion, the crew began powering up the Lunar Module at the direction of Ground Control, intending to use it as a lifeboat—an eventuality that had been examined in some depth during training for Apollo 10. At that time, NASA discarded the idea as impractical, but in typical NASARead More – Source
[contf] [contfnew] 
arstechnica
[contfnewc] [contfnewc]
The post The Greatest Leap, part 5: Saving the crew of Apollo 13 appeared first on News Wire Now.








{kind=link}